Structures and Architectures for Optimizing Database (EN)
Recently, I read the XtraDB part of Percona Server document roughly, in this process, I realized my huge lack of basic database knowledge, so it’s inevitable to spend a lot of time on clarifying many concepts which have been mentioned several times in the doc.
In the meanwhile, I found out that there’s so much incorrect and ambiguous information on the internet, for the greater good, it could be great if I organize these all materials and post them on this blog. This article contain a few MySQL only usage, but it’s won’t cut down the readability for the reader who is not familiar with MySQL (perhaps…).
Why use English? Due to most of the info I collect are written in English and I don’t have enough time to translate them. But don’t worry, I’ll post a Chinese version someday.
Brief Intro
As data growth, the performance of database server will become worse gradually. When there are only hundreds of rows in a table, we basically don’t need to care about the quality of query statements, but once a query involves hundred of thousand of rows, that could be an issue.
To ease this problem, MySQL 5.7 provides the MAX_EXECUTE_TIME feature to avoid your query sucks. (more)
But what if we have hundred of millions of data in the server? That won’t be that simple. Fortunately, developers have multiple ways to deal with performance problems.
Partition
Partition is the way to split the data of a table into multiple tables by rows or columns, according to different divides, it can be classified into Horizontal Partition and Vertical Partition.
Horizontal Partition

Vertical Partition
(MySQL 5.7 does not support it)

Obviously, Partition can reduce the effort of querying the tables with fewer indexes and the amounts of data, but the shortcomings are also evident:
- Developers need to spend more resources to maintain the data.
- The capability of execution is the bottleneck because there’s still one server deals with all commands.
- Almost zero benefit for operations of whole table select, insert, update and delete.
Sharding
A database shard is a horizontal partition of data in a database.
– Wikipedia, “Shard (database architecture)“
Sharding is a type of horizontal partition, the rows in a table will be separated into multiple tables, and the most important is, these tables will be stored on the different servers. So it’s possible that the system needs to get order data of user_A from DB_01 and user_B from DB_02.

Some articles say that Sharding is Horizontal Partition and Horizontal Partition is Sharding, but it’s not perfectly true because the Horizontal Partition describes the data in a large table is divided by rows and stored in the multiple relative small tables whether in the same or different server(s).
Like the cons of Partition, although Sharding solves the bottleneck of execution capability through multiple machines collaboration, it leads to the data scattered in the different tables of various database servers, so it’s still a pain in the ass to maintain these shards.
Replication
Database Replication is a mechanism of automatically copying the data from a database to another one. With database Replication, it’s much easier to have multiple database servers provide service to meet the increasing demands.
Roles
There are two roles in the database Replication:
- Master Server is available to handle both read and write (CRUD) operations, and the data in master will replicate to slave(s).
- Slave Server can only read the data from its disk.
Since the data in Slave Server is synchronized from Master Server, it could cause some serious consistency problems. When the data updated in Master Server and the replication hasn’t performed or is performing, the user may get old data from Slave Server.
Topology for Database Replication
Here come some common relationships for database Replication.
Master/Slave(s)

Master/Master
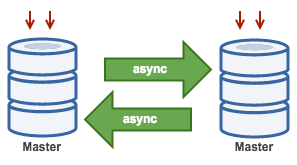
Others (more)
ex. Multi-Source Replication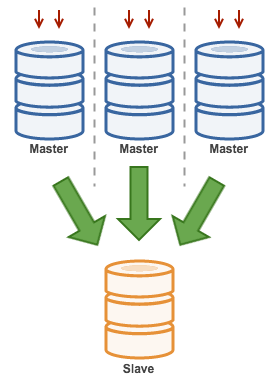
- Check this if you’re curious how does MySQL replication work.
Clustering
Clustering means many database servers (usually named nodes) operating in a group, there are multiple ways to do this.
Common Scenario
The most common scenario is, several nodes access the same centralized shared disk, most of nodes used for reads and only one for write (CRUD) operations.

This method provides a better performance of reading data, in additional, once a failure rises in a node, another node will take over the task (this feature is named failover).
But it also has obvious Achilles’ heel, limited scalability, first, there’s only one DB node takes charge of CRUD operations; second, the read limitations are particularly evident when an application requires complex joins or contains non-optimized SQL statements.
Advanced Clustering
Advanced clustering techniques rely on real-time memory replication between nodes, keeping the memory image of nodes in the cluster up to date via a real-time messaging system.

Every node is available to operate both reading and writing, but it’s limited by the amount of traffic between nodes (usually using the typical network or other high-speed communication mechanisms). When the nodes are added to the cluster, the communication and memory replication overhead increases geometrically. Since the severe scalability limitation, it’s often with a relatively fewer number of nodes.
This solution also suffers from the same shared disk limitations of a traditional cluster, given that a growing, single large database has increasingly intensive disk I/O.